Denna artikel beskriver hur man kan ansluta till FläktWoords FTX ventilation till sin Home Assistant installation.
Bakgrund
Jag har nyligen flyttat till ett hus med ett RDAF midi FTX aggregat från FläktWoods med kontrollpanelen CURO Touch RDKZ-41-3 som tillbehör. När jag klickade runt i menyerna på kontrollpanelen insåg jag att det fanns en del inställningar för modbus vilket gjorde mig nyfiken. Dessutom insåg jag ganska snabbt att det vore en stor fördel att kunna styra aggregatet på distans. Dels för att styra börvärden, men också för att automatisera detta. Till exempel när huset värmts upp under en varm sommardag, då vill man gärna kunna ställa ner börvärdet på tilluften alternativt stänga av värmeåtervinningen helt. På vintern däremot vill man gärna maximera värmeåtervinningen och kanske dra ner på flödet riktigt kalla dagar.
Modbus på FTX-aggregatet
Efter lite letande på FläktGroups webplats hittade jag dokumentation för aggregatet och styrkortet som visade att det fanns utgång för modbus (RS485).
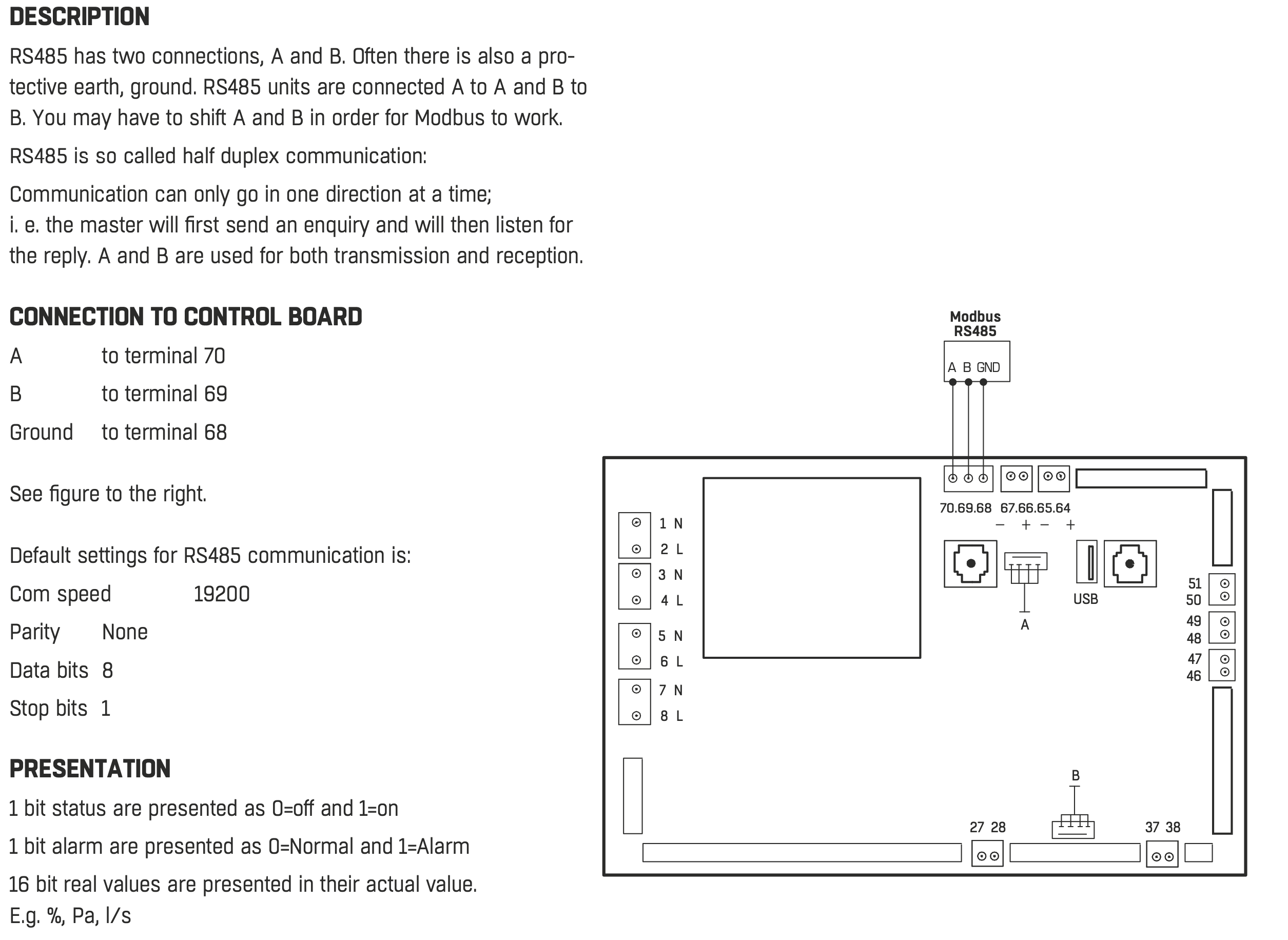
Efter lite mer forskande och kontakt med supporten fick jag faktiskt hemskickat den skruvplint som passade för styrkortet.

Skruvplint
Efter det så tittade jag fysiskt på aggregatet och hittade styrkortet och den aktuella porten. Orienteringen på kortet var lite annorlunda med anslutningsnummer 70,69,68 stämde med dokumentationen.

Ingång för modbus
Modbus over tcp/ip
För att på ett enkelt sätt kommunicera med en modbus-enhet från Home Assistant började jag leta efter en lämplig gateway. Efter ett tag hittade jag en gateway från WaveShare som verkade göra vad jag är ute efter. Enligt dokumentationen kan den göra ganska mycket, men själv översätter jag bara modbus tcp/ip till modbus över rs485.
Du hittar produkten här https://www.waveshare.com/product/rs485-to-eth-b.htm men det finns en rad olika webbutiker som säljer den.

Modbus Gateway
När du ansluter gatewayen till nätverket kommer den att fråga efter en IP med DHCP, därefter kan du ansluta till enheten med en vanlig webläsare och konfigurera enheten.
När detta är gjort är det sista arbetet att dra kablage mellan aggregatet och modbus gateway. Du kan förslagsvis använda vanligt CAT-kablage. Dessa kopplas sedan dels till gatewayen och dels till skruvplinten som i sin tur ansluts till aggregatet. Var noga med att ansluta rätt kabel till rätt port, A till A, B till B och jord till jord.
Jag ägnade en hel del tid med att felsöka och labba innan jag hittade en inkoppling och konfiguration som verkade fungera, men såhär ser min konfiguration ut idag:
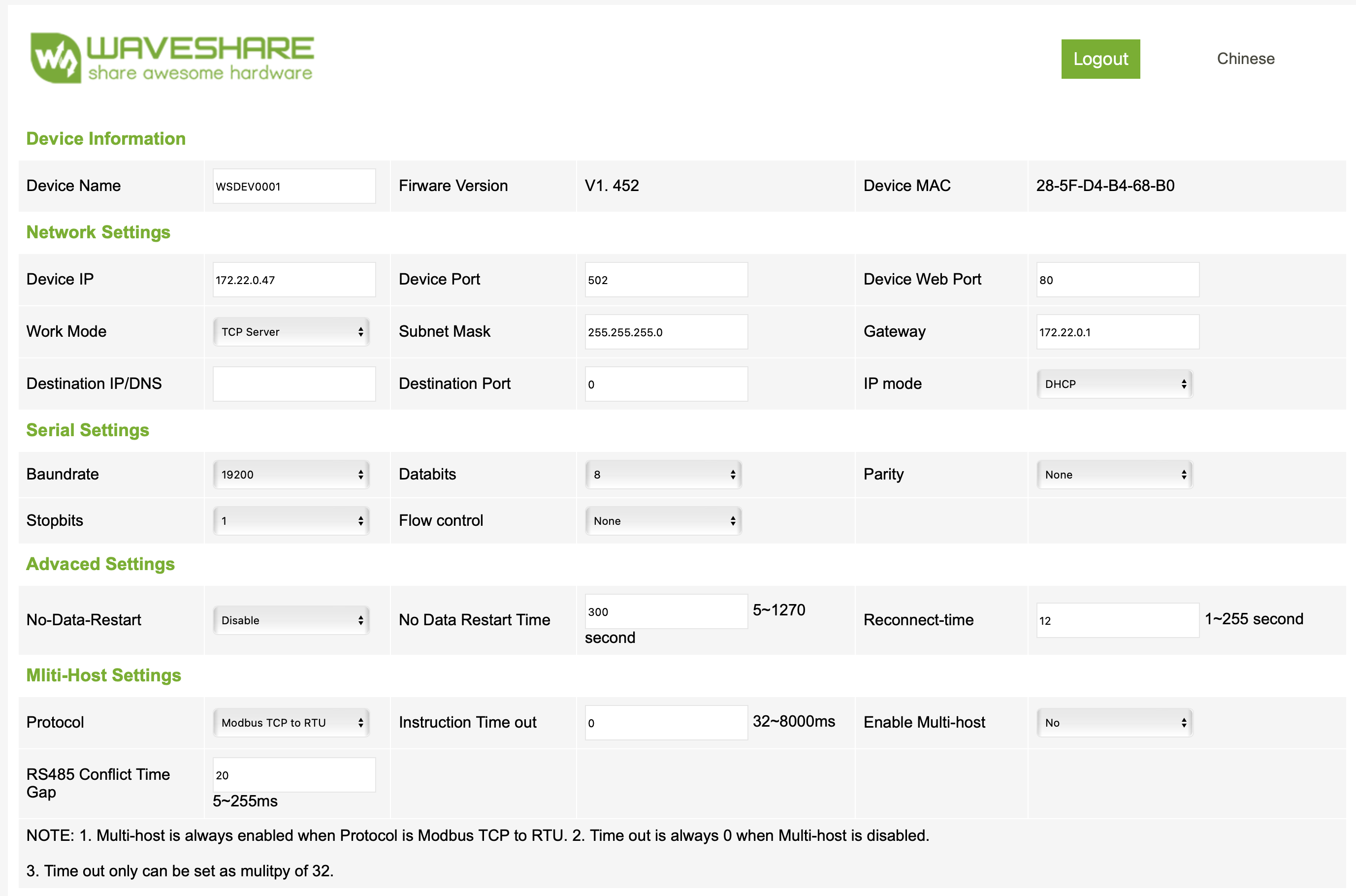
Konfigurationsinterface för waveshare modbus gateway
Om du har problem att få igång modbus-trafiken så underlättar det att ha en modbus-porgramvara på datorn där du kan testa olika register, slav-adresser osv. Om du har problem att få igång det kan du behöva switcha A och B på gateway-sidan enligt dokumentationen ovan.
Dokumentation om vilka register osv som gäller hittar du på FläktGroups webbplats: https://www.flaktgroup.com/api/v1/Documents/699dada6-4648-44ca-aca3-6813be8ec08b/
Home Assistant
När du har en fungerade modbus-anslutning återstår bara att konfigurera upp “thermostater” sensorer och binära sensorer i home assistant. För detta utgick jag från FläktGroups modbus dokumentation som du hittar på deras webbplats: https://www.flaktgroup.com/api/v1/Documents/699dada6-4648-44ca-aca3-6813be8ec08b/
Här är min kompletta konfiguration vilket innefattar grundinställning för modbus, en klimat/thermostat, binära sensorer, samt sensorer. Notera att register-adresserna saknar de inledande 40, jag vet inte varför, men använder jag hela adressen fungerar det inte för mig.
modbus:
- name: ftx
type: tcp
host: 172.22.0.47
port: 502
climates:
- name: "FTX Ventilation"
address: 25
input_type: holding
slave: 2
count: 1
min_temp: 7
target_temp_register: 49
scale: 0.1
binary_sensors:
- name: Brandlarm (FTX)
address: 94
input_type: coil
slave: 2
- name: Fel tilluftssensor (FTX)
address: 95
input_type: coil
slave: 2
- name: Fel uteluftsensor (FTX)
address: 96
input_type: coil
slave: 2
- name: Fel frånluftssensor (FTX)
address: 97
input_type: coil
slave: 2
- name: Fel värmeväxlare (FTX)
address: 111
input_type: coil
slave: 2
sensors:
- name: flakthastighet (FTX)
address: 202
input_type: holding
slave: 2
- name: Temperatur tilluft (FTX)
unit_of_measurement: '°C'
device_class: temperature
slave: 2
address: 25
scale: 0.1
precision: 1
- name: Temperatur uteluft (FTX)
unit_of_measurement: '°C'
device_class: temperature
slave: 2
address: 26
scale: 0.1
precision: 1
- name: Temperatur frånluft(FTX)
unit_of_measurement: '°C'
device_class: temperature
slave: 2
address: 27
scale: 0.1
precision: 1
- name: Luftfuktighet tilluft (FTX)
unit_of_measurement: '%'
device_class: humidity
slave: 2
address: 35
- name: Luftfuktighet frånluft(FTX)
unit_of_measurement: '%'
device_class: humidity
slave: 2
address: 36
- name: Fläkthastighet tilluft(FTX)
unit_of_measurement: '%'
slave: 2
address: 41
- name: Fläkthastigt frånluft (FTX)
unit_of_measurement: '%'
slave: 2
address: 42
- name: förrvärme tilluft(FTX)
unit_of_measurement: '%'
slave: 2
address: 43
- name: Eftervärme tilluft(FTX)
unit_of_measurement: '%'
slave: 2
address: 44
- name: Värmeåtervinning(FTX)
unit_of_measurement: '%'
slave: 2
address: 46
- name: Börvärd ventilion (FTX)
unit_of_measurement: '°C'
device_class: temperature
slave: 2
address: 49
scale: 0.1
När du lagt till ovan i konfigurationen och startat om Home Assistant bör du verifiera att allt fungerar via Developer Tools. Om du ser rimliga värden för temperaturer osv, så kommunicerar troligen Home Assistant korrekt med aggregatet och då är det dags att skapa en dashboard för styrningen. Nedan finns ett exmpel på hur en sådan kan se ut.
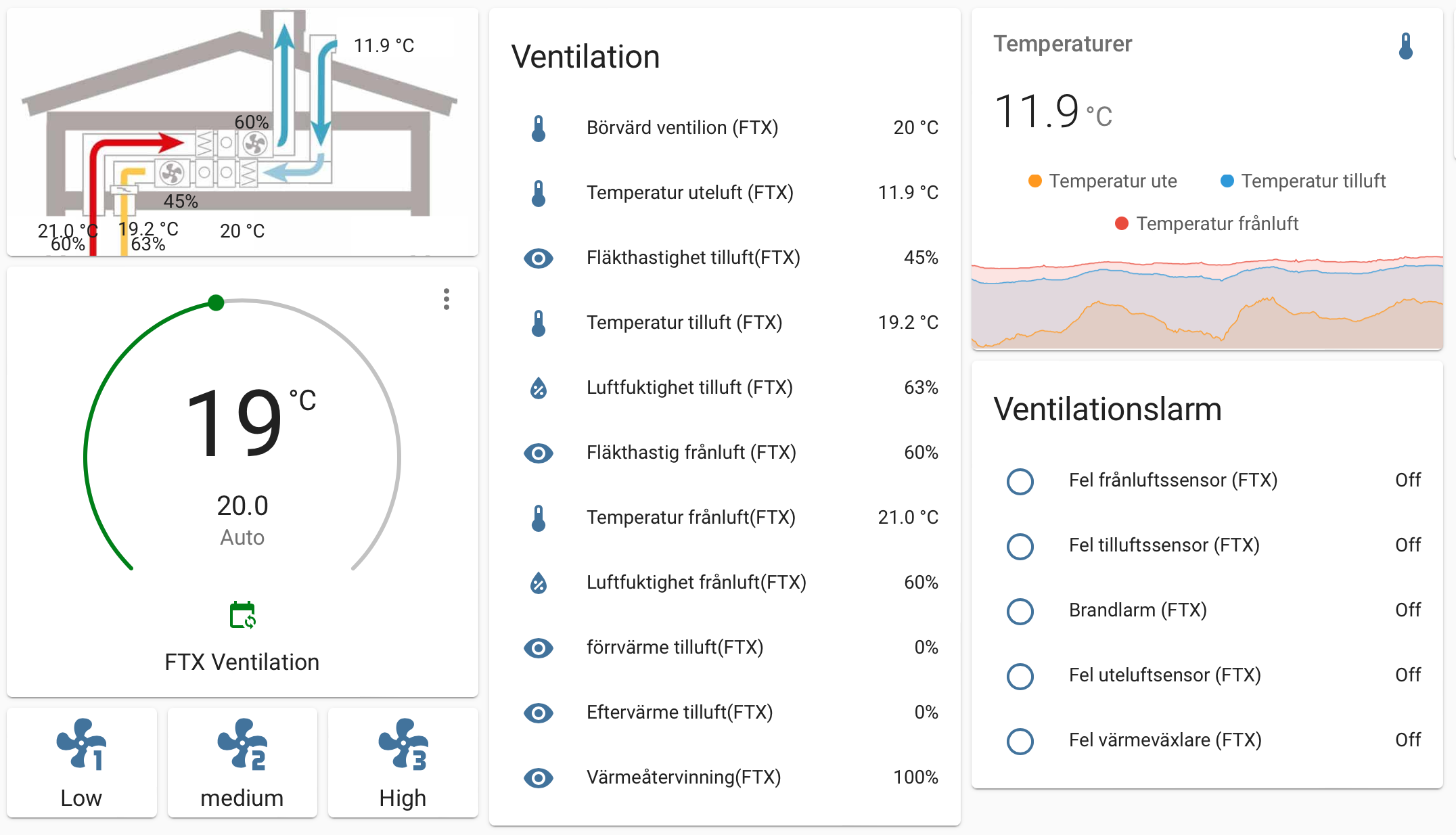
Enkel dashboard i Home Assistant
För att styra fläkthastigheten behöver du sätta ett register till 0,1,2 beroende på om du vill ha låg, medium eller högt flöde. Detta görs via en service “Modbus: Write register”. Registret som ska sättas är 202 och slav-adressen är i mitt fall 2 vilket troligen är standardinställningen.
Verifiera att det fungerar genom att titta på kontrollenheten samtidigt som du skriver till registret, om motsvarande förändring syns på skärmen har du lyckats.